背景
在日常开发中,常常需要安排任务在未来的某个时间点执行,这就是所谓的定时任务(schedule task)。定时任务有很多解决方案,而 crontab 作为 Linux 上的预装工具而广为人知。今天我们来了解一下,crontab 作为定时任务的一种技术方案具有哪些特点。
crontab 功能特性
crontab 主要有三个方面的功能特性:
- crontab 支持定义精度到分钟级别的任务。
- 系统上的用户提供了相互独立的配置。
- 要运行的任务必须能够在 shell 命令行中执行。
关注的问题
本篇文章主要想要从定性的角度回答下面几个问题
- crontab 如何实现 schedule task 功能
- 一个任务是否可能无法在指定的时间被执行
crontab 技术实现细节
要回答前面的问题,我们需要了解 crontab 的技术实现。crontab 使用典型的 forever loop + fork/exec 技术方案,主进程循环匹配待执行的任务,当有匹配的任务需要执行时,会 fork 出子进程来执行。在有了这个大概的概念之后,我们现在来进入实现细节。
重要的数据结构
在这之前,我们先认识一下 crontab 与运行相关的三个重要的数据结构和变量。
- TargetTime: TargetTime 存储的是每分钟的开始时间(每分钟的0秒),用于表示当前执行周期的时间。执行逻辑会借助 TargetTime 的值来判断当前周期剩余时间,以及用于筛选当前周期需要执行的任务。
- job_queue(jhead/jtail): 它对应一个链表结构,存储的是已经匹配到的任务。jhead 和 jtail 分别存储该链表的首尾。为了后续表述方便,我将使用 job_queue 作为该链表的名称
- database: 用于存储所有配置的任务。这些任务配置以所要使用的用户角色权限为维度存储在不同的链表中
总体执行流程
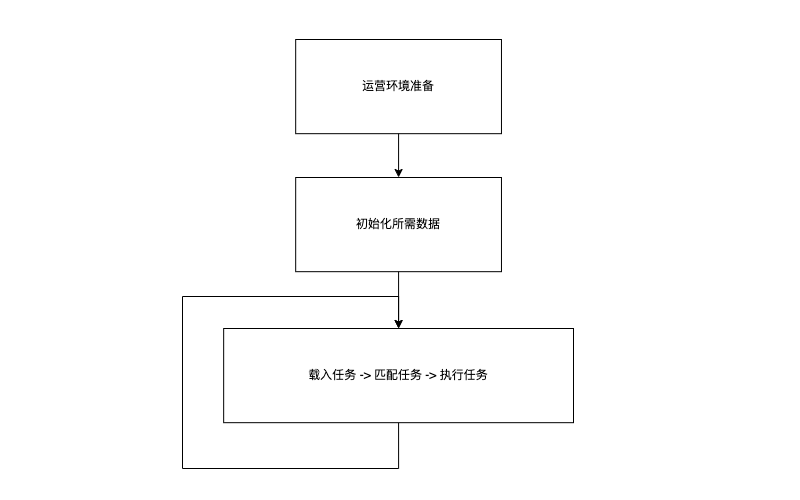
crontab 守护进程启动后,它会完成以下3个方面的工作:
- 进行运行环境的准备工作
- 解析启动参数,主要识别是否开启了 debug 模式;
- 设置系统信号处理逻辑;
- 对 pid 文件进行加锁,保证只有一个进程在运行;
- 设置进程的工作目录和 root 身份;
- fork 出子进程,并让子进程变成守护进程,启动进程退出;
- 初始化任务相关的变量
- 初始化 database,载入所有定义的任务;
- 将那些执行时间定义为"crontab 重启"时的任务加入到 job_queue 中;
- 初始化 TargetTime 为当前时间的*下一分钟的0秒* (函数: cron_sync);
- 执行任务循环
- 尝试执行匹配到的任务;
- 检查配置是否有更新,载入更新后的任务;
- 匹配新的任务;
- 更新 TargetTime 到下一执行周期时间;
任务匹配与执行逻辑
crontab 核心逻辑就在“执行任务循环”中。
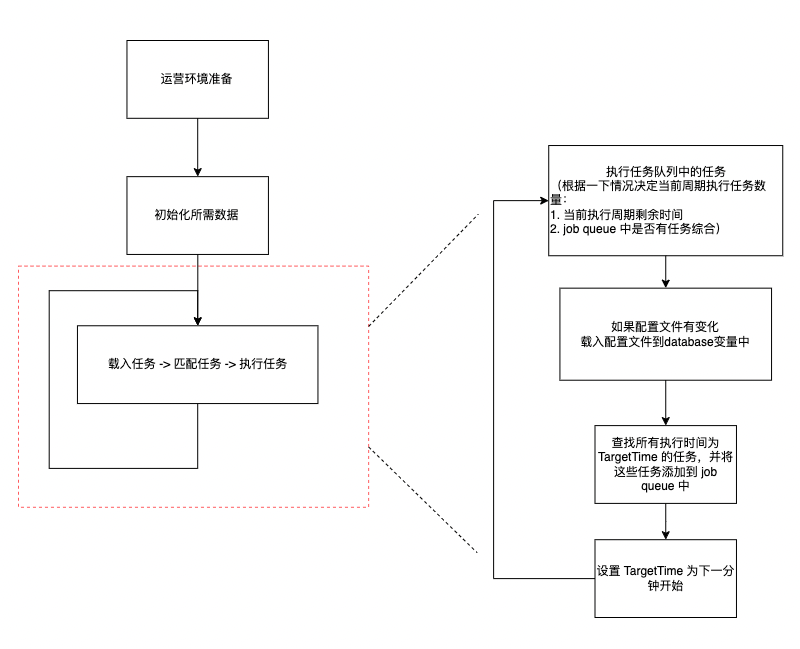
在深入到这些逻辑之前,我们需要注意到 crontab 中“载入文件配置”、“匹配需要执行的任务”、“触发任务执行”都是在一个进程中完成,如果这三个步骤中有一步非常耗时,那么定义的任务就可能没有办法在指定的时间触发执行。所以 crontab 需要做一些针对性的优化来尽量保证任务按照预期执行
下面我们深入每个步骤的逻辑细节
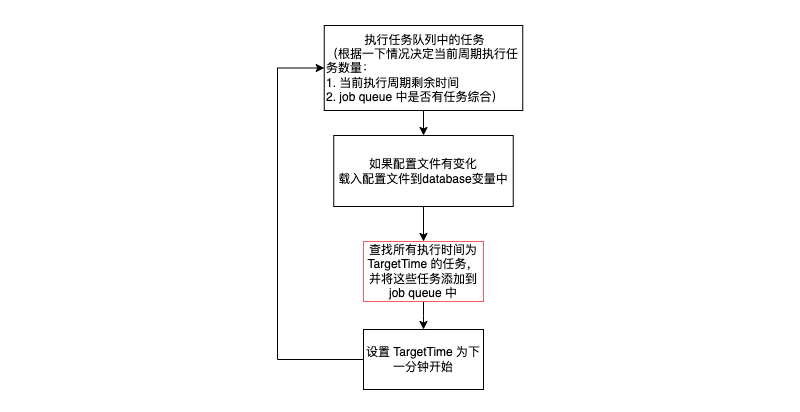
尝试执行匹配到的任务
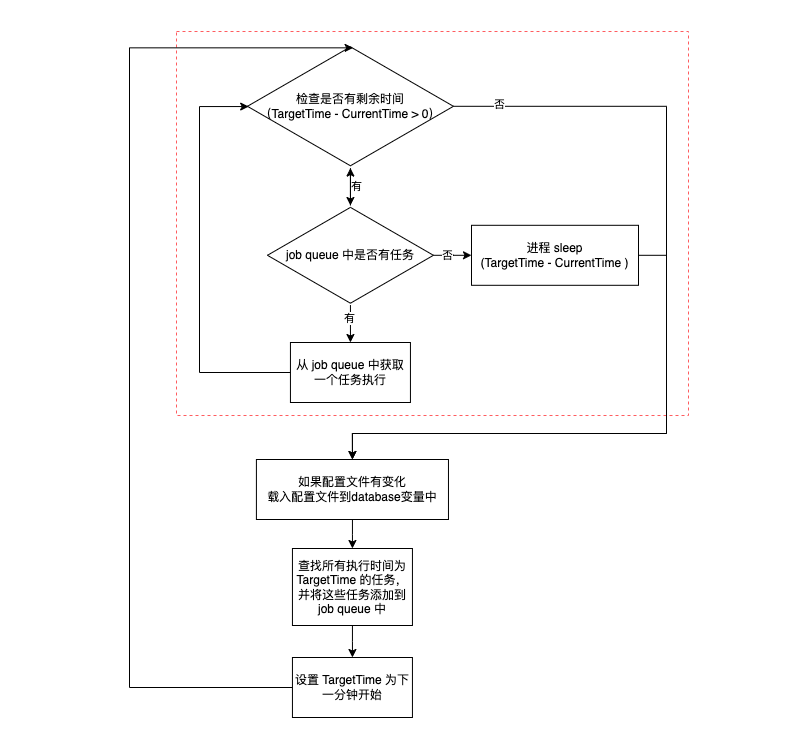
上图比较具体的介绍相关逻辑。需要额外注意的是,一个任务要被触发执行,除了需要被添加到 job_queue 中,还需要保证当前执行周期有剩余时间(TargetTime - CurrentTime > 0)。这样做是为了避免 job_queue 中存在过多的任务阻碍后续逻辑执行,导致下一个周期的任务被遗漏。虽然这种方法不能确保定义的任务在准确的时间触发执行,但它能够保证每个周期准时开始,从而确保每个周期的时间是确定的。
除此之外,crontab 会为每个任务 fork 出子进程来执行具体的逻辑,从而让主进程能够正常运行,保证任务执行精度。但是 fork 出的子进程并不是直接用于执行 shell 命令,而是会再 fork 出1到2个子进程来协同完成任务。进程协作方式如图所示:
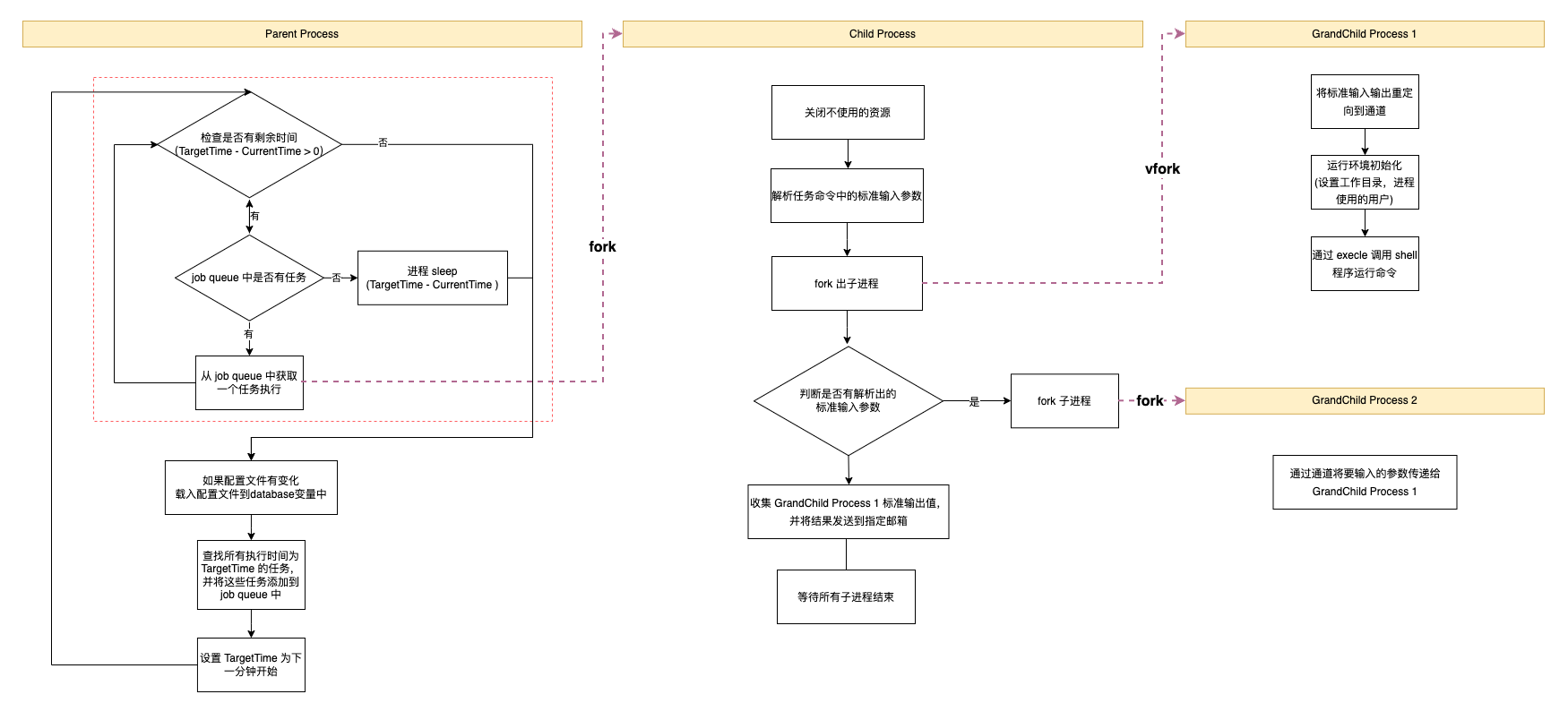
这些进程的分工如下:
- Child Process(由主进程 fork 出来进程): 主要职责是设置任务运行环境、预处理任务命令、监听任务执行结果并发送邮件
- GrandChild Process 1(Child Process vfork 出来的进程):主要就是执行任务中的 shell 命令
- GrandChild Process 2(如果执行的任务有标准输入,Child Process 会 fork 出该进程):主要是为了给 GrandChild Process 1 执行的 shell 任务从标准输入提供参数
一些技术细节:
为什么需要 GrandChild Process 2?
使用 GrandChild Process 2 来提供标准输入主要是为了避免一种极端情况:当参数大小超过通道 buffer 的限制时,如果通道里面的数据没有人去接受(比如任务不会读取标准输入数据),那么进程再尝试往通道写入数据时会被 block, 无法正常执行后续“监听任务输出数据”的逻辑。
为什么要用 vfork?
vfork 出现主要是解决早期 fork 调用性能差的问题(早期 fork 子进程时,子进程需要将父进程的数据完全拷贝一份)。在 fork 方法优化之后,vfork 在性能上不再有很大优势,同时 vfork 在使用上有许多注意事项,所以该方法慢慢被废弃,在某些系统中 vfork 与 fork 的行为是一样的。更多具体详细情况可以查看上面的链接。
从这里看出每个任务执行至少需要产生 2 个进程。如果同一时间有大量任务需要执行,或者有很多任务需要花费很长时间执行,就会需要需要很多进程。
检查配置并载入配置
“载入配置”这部分没有什么特殊的逻辑,我们只是需要了解一下 crontab 的任务配置文件存放位置。系统中每位用户都有一份单独的 crontab 配置,它们用用户名作为文件名称存放 /var/spool/cron/crontabs 目录下。同时在 /etc/crontabs/root 文件中存储了一份系统的 crontab 配置文件。 配置检查和载入的逻辑如下:
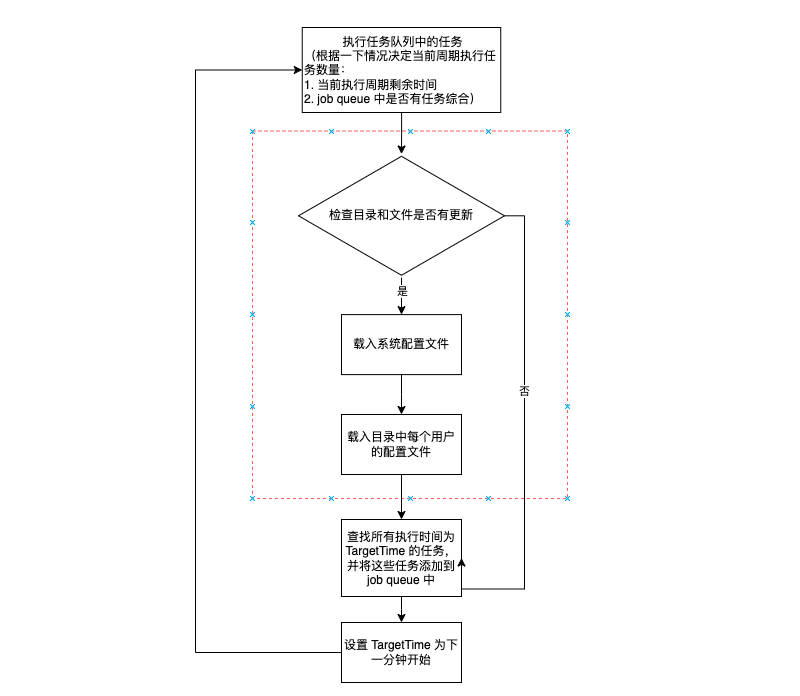
匹配任务
这里主要的逻辑是将 database 中的配置依次与 TargetTime 进行比较,相匹配的则放入 job queue 中等待执行。
回到问题
我们在文章前面提到了两个问题。到这里我们已经知道对问题1已经有了足够的了解。
对于问题2,从上面流程分析中能够大概定性了解一些可能存在的瓶颈。从任务匹配到任务真正被执行,可能存在的瓶颈主要在“配置文件载入”和 fork 进程。文件操作相对较慢,但是从 crontab 使用场景来说不太可能有大量的文件需要载入,这部分在实际使用中正常情况下不会成为操作瓶颈。而 fork 是相对容易出现瓶颈的,一般来说 linux 会限制每个进程需要 fork 的数量,如果 crontab 在同一时间有大量任务需要执行,就需要 fork 出至少2倍于任务数量的进程来完成,这样就很容易超出系统的限制。在 fork 失败的情况下,crontab 就会放弃执行当前的任务。所以 crontab 并不能保证任务在准确的时间执行。